複数CSVを一致する列で統合
先日、サービスのリプレイスに伴いデータ移行を担当しました。
その際にPythonのデータ解析ライブラリPandas(パンダス)を用いてCSVの整形を行いました。
普段使用しないPythonですが、
使ってみたらCSVのデータ整形にかなり便利でしたのでご紹介させていただきます。
概要
Pandasのmerge関数を使用して、複数CSVを統合します。
merge関数はSQLのjoinのような役割を果たしてくれます。
サンプルコード
import pandas as pd
OLD_ARCHIVE_CSV_PATH = 'old_archive_list.csv'
NEW_ARCHIVE_CSV_PATH = 'new_archive_list.csv'
def main():
df1 = pd.read_csv(OLD_ARCHIVE_CSV_PATH)
df2 = pd.read_csv(NEW_ARCHIVE_CSV_PATH)
result = pd.merge(df1, df2, left_on='post_title', right_on='title', how='left')
new_result = result.rename(columns={'id': 'new_archive_id'})
df_out = new_result.loc[:, ['new_archive_id', 'archive_id']]
df_out.to_csv('~/Desktop/archive_ids.csv', index=False, float_format='%.0f')
if __name__ == '__main__':
main()
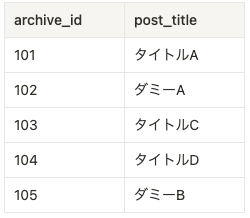
サンプルコードで登場するCSVの内容
old_archive_list.csvのデータ
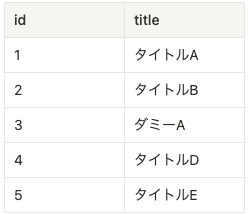
new_archive_list.csvのデータ
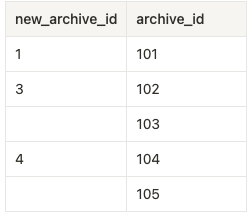
archive_ids.csvのデータ(出力されるCSV)
サンプルコードの各行の詳細
①Pandasをimportして別名を付けています。
import pandas as pd②対象となるCSVを読み込んでいます。
OLD_ARCHIVE_CSV_PATH = 'old_archive_list.csv'
NEW_ARCHIVE_CSV_PATH = 'new_archive_list.csv'
def main():
df1 = pd.read_csv(OLD_ARCHIVE_CSV_PATH)
df2 = pd.read_csv(NEW_ARCHIVE_CSV_PATH)③merge関数を使用して、2つのCSVを統合しています。
result = pd.merge(df1, df2, left_on='post_title', right_on='title', how='left')↑を言語化すると↓のようになります。
merge(CSV1, CSV2, left_on='CSV1の結合キー', right_on='CSV2の結合キー', how='結合方法')オプションの詳細
ON
結合するキーを指定します。
merge(CSV1, CSV2, on='結合キー', how='結合の方法')how
inner
内部結合によって左右でお互い一致するデータを残します。
result = pd.merge(df1, df2, left_on='post_title', right_on='title', how='inner')結合結果
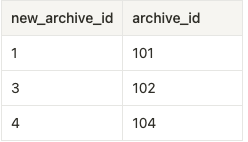
left
左結合によって左に一致するデータを残します。
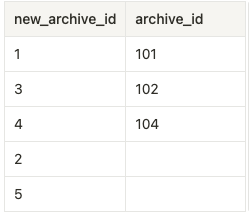
right
右結合によって右に一致するデータを残します。
result = pd.merge(df1, df2, left_on='post_title', right_on='title', how='right')結合結果
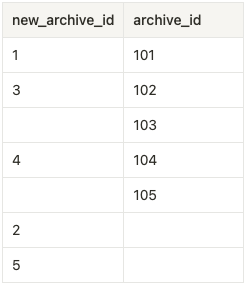
outer
外部結合によって左右両方のデータを残します。
result = pd.merge(df1, df2, left_on='post_title', right_on='title', how='outer')結合結果
④カラム名をidからnew_archive_idに変更しています。
new_result = result.rename(columns={'id': 'new_archive_id'})⑤出力する項目をnew_archive_idとarchive_idのみにし、順番を指定しています。
df_out = new_result.loc[:, ['new_archive_id', 'archive_id']]⑥CSVを出力しています。
df_out.to_csv('~/Desktop/archive_ids.csv', index=False, float_format='%.0f')オプションの詳細
index=False
indexの有無です。
デフォルトはTrueになっています。
float_format='%.0f'
小数点以下をなくしています。
浮動小数点数floatの書式を指定できます。
結合時にレコードにnanが入る場合は数字の末尾に.0がついてしまうので追加しています。
例)1 → 1.0
以上、複数CSVを一致する列で統合する方法でした。
この他にもCSVの整形をする上で、便利だった関数があったのでご紹介していこうと思います。